
Microsoft VALL-E 2: Sprachmodell zu gut f├╝r die Welt?

Aufbauend auf dem Vorg├żnger VALL-E f├╝hrt die Weiterentwicklung als VALL-E 2 zwei Verbesserungen ein: Repetition Aware Sampling verfeinert das urspr├╝ngliche Nukleus-Sampling-Verfahren, indem es die Wiederholung von Token in der Dekodierungshistorie ber├╝cksichtigt. Dadurch wird nicht nur die Dekodierung stabilisiert, sondern auch das in VALL-E auftretende Problem der Endlosschleife umgangen. Grouped Code Modeling organisiert Codec-Codes in Gruppen, um die Sequenzl├żnge effektiv zu verk├╝rzen, was nicht nur die Inferenzgeschwindigkeit erh├Čht, sondern auch die Herausforderungen der Modellierung langer Sequenzen angeht. Microsoft bezieht sich dabei auf eigene Versuche mit den LibriSpeech- und VCTK-Datens├żtzen die gezeigt haben sollen, dass VALL-E 2 fr├╝here Zero-Shot-TTS-Systeme in Bezug auf Sprachrobustheit, Nat├╝rlichkeit und Sprecher├żhnlichkeit ├╝bertrifft. Es ist das erste System seiner Art, das bei diesen Benchmarks die Parit├żt zum Menschen erreicht. Dar├╝ber hinaus synthetisiert VALL-E 2 durchg├żngig hochwertige Sprache, selbst bei S├żtzen, die aufgrund ihrer Komplexit├żt oder sich wiederholender Phrasen traditionell schwierig sind.
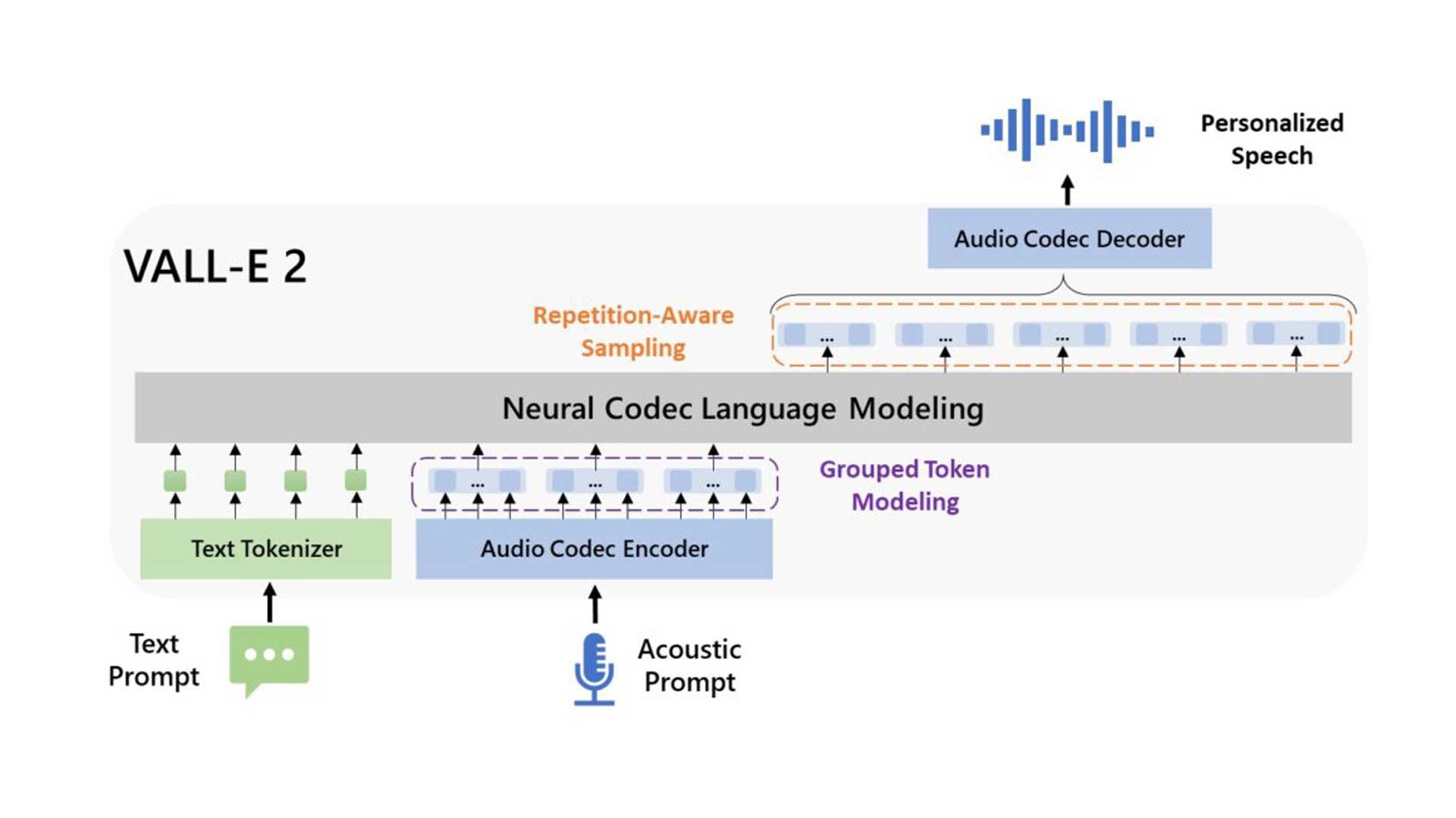
Die gruppierte Codemodellierung soll nicht nur die Inferenz durch Verringerung der Sequenzl├żnge beschleunigen, sondern auch die Leistung verbessern, indem sie das Problem der Modellierung langer Kontexte entsch├żrft. Basierend auf der Token-Wiederholung in der Dekodierungshistorie erh├Čht das wiederholungsbewusste Sampling die Stabilit├żt des Dekodierungsprozesses und umgeht das Problem der Endlosschleife, das in VALL-E auftritt.
VALL-E 2 kann zwar mit einer Stimme sprechen, die der des Sprechers gleicht, aber die ├ähnlichkeit und Nat├╝rlichkeit h├żngen von der L├żnge und Qualit├żt der Sprachansage, den Hintergrundger├żuschen und anderen Faktoren ab. Dennoch, oder gerade deshalb dient die Ver├Čffentlichung nur zu Forschungszwecken und es gibt keine Pl├żne, VALL-E 2 in ein Produkt zu integrieren oder den Zugang f├╝r die ├¢ffentlichkeit zu erweitern. VALL-E 2 k├Čnnte Sprache synthetisieren, die die Identit├żt des Sprechers beibeh├żlt. N├╝tzlich k├Čnnte dies f├╝r Lernzwecke, Unterhaltung, journalistische Zwecke, selbst erstellte Inhalte, barrierefreie Funktionen, interaktive Sprachdialogsysteme, ├£bersetzungen, Chatbots usw. sein. Wer sich selbst davon ├╝berzeugen will, dem sei ein Blick auf die Projektseite empfohlen, wo es, nat├╝rlich in englischer Sprache, reichlich H├Črbeispiele und Vergleiche gibt.
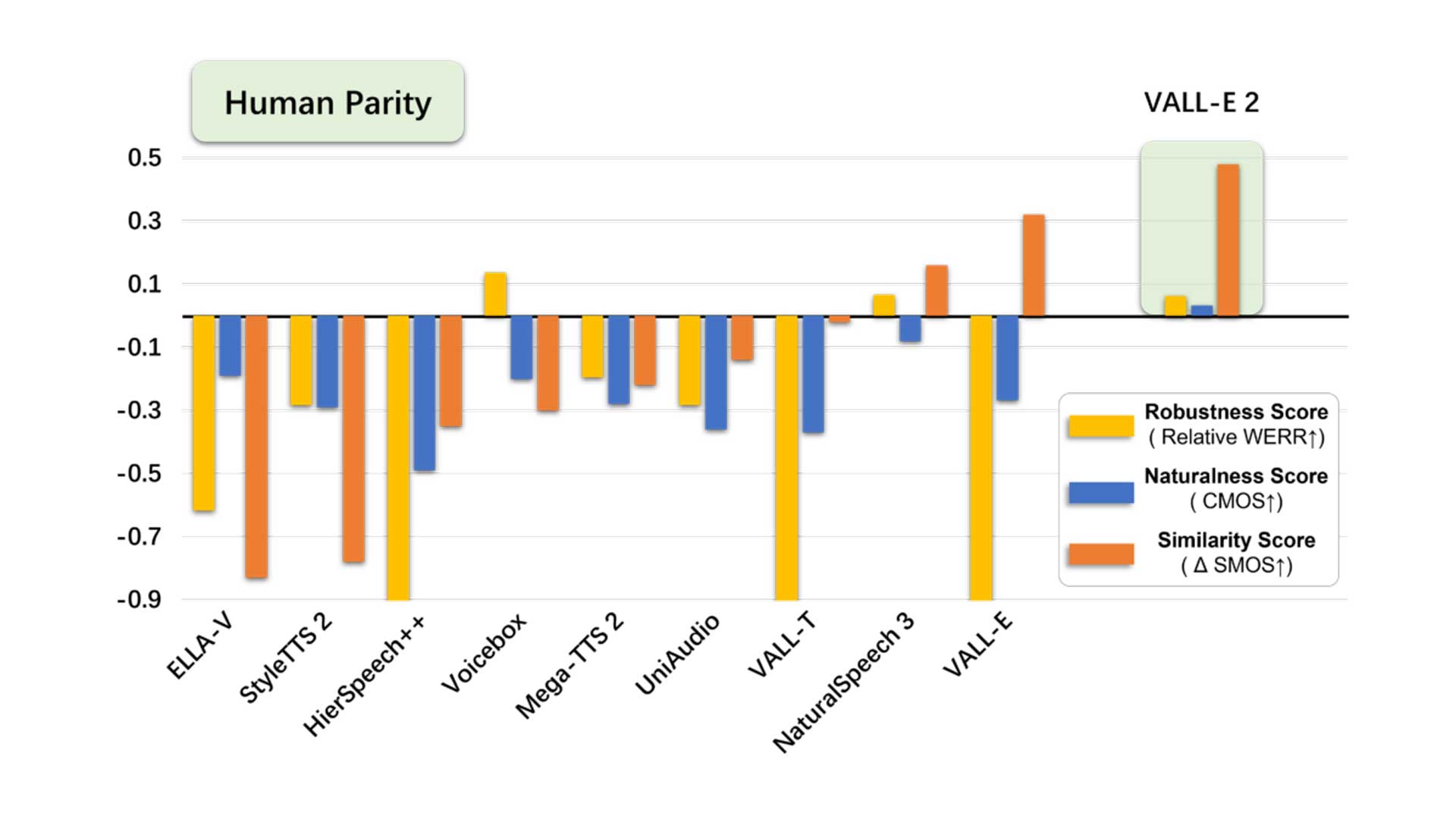
Human Parity bedeutet, dass die Robustheit, Nat├╝rlichkeit und ├ähnlichkeitsmetriken von VALL-E 2 die der GroundTruth-Samples ├╝bertreffen. Damit soll VALL-E 2 akkurate, nat├╝rliche Sprache in der exakten Stimme des Originalsprechers erzeugen k├Čnnen und vergleichbar mit der menschlichen Leistung sein. Allerdings bezieht sich diese Aussage ausschlie├¤lich auf die experimentellen Ergebnissen der LibriSpeech- und VCTK-Datens├żtze.
Doch Microsoft sieht selbst die Gefahr, dass das Modell missbraucht wird, z. B. zur F├żlschung der Stimmerkennung oder zur Nachahmung eines bestimmten Sprechers. Man betont, dass man die Experimente unter der Annahme durchgef├╝hrt hat, dass der Benutzer zustimmt, der Zielsprecher in der Sprachsynthese zu sein. Um dieses Sprachmodell wirklich zu ver├Čffentlichen und auf unbekannte Sprecher in der realen Welt anwendbar zu machen, sollte es ein Protokoll enthalten, das sicherstellt, dass der Sprecher der Verwendung seiner Stimme und eines synthetischen Spracherkennungsmodells zustimmt, meint Microsoft.
KI in der Videoproduktion: passende Tools und wichtige Tipps
News├╝bersicht: Kamera
Link zum Hersteller: Microsoft - VALL-E 2








